Intégrer et unionner les données
Dans la modélisation Data Vault, nous utilisons les hubs pour intégrer les données. C'est l'une des principales raisons pour lesquelles nous choisissons la modélisation Data Vault.
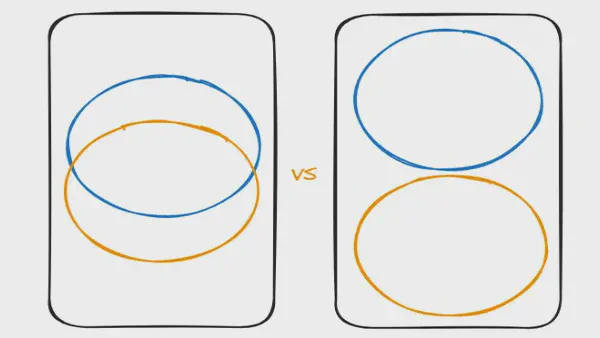
Unionner versus intégrer des hubs — pourquoi ça compte Dans la modélisation Data Vault, nous utilisons les hubs pour intégrer les données. Tout le monde le sait. C’est l’une des principales raisons pour lesquelles nous choisissons la modélisation Data Vault : intégrer les données provenant de diverses sources. Mais que signifie « intégration » ? Jusqu’à présent, je n’ai pas vu de discussion sur la façon dont nous intégrons réellement les données.
Dans cet article, je simplifierai mes exemples, sachant que la réalité peut être plus complexe que ce qui est présenté ici. Cependant, pour établir le concept principal, il devrait être utile de garder les choses simples.
Lors de discussions avec Carsten Schweiger, nous avons identifié deux patterns différents : Intégration et Unionnement.
Intégration vs. Unionnement
Cette distinction est importante car elle change la façon dont nous pouvons traiter les données de manière optimale. Caractérisons les deux options :
Intégration
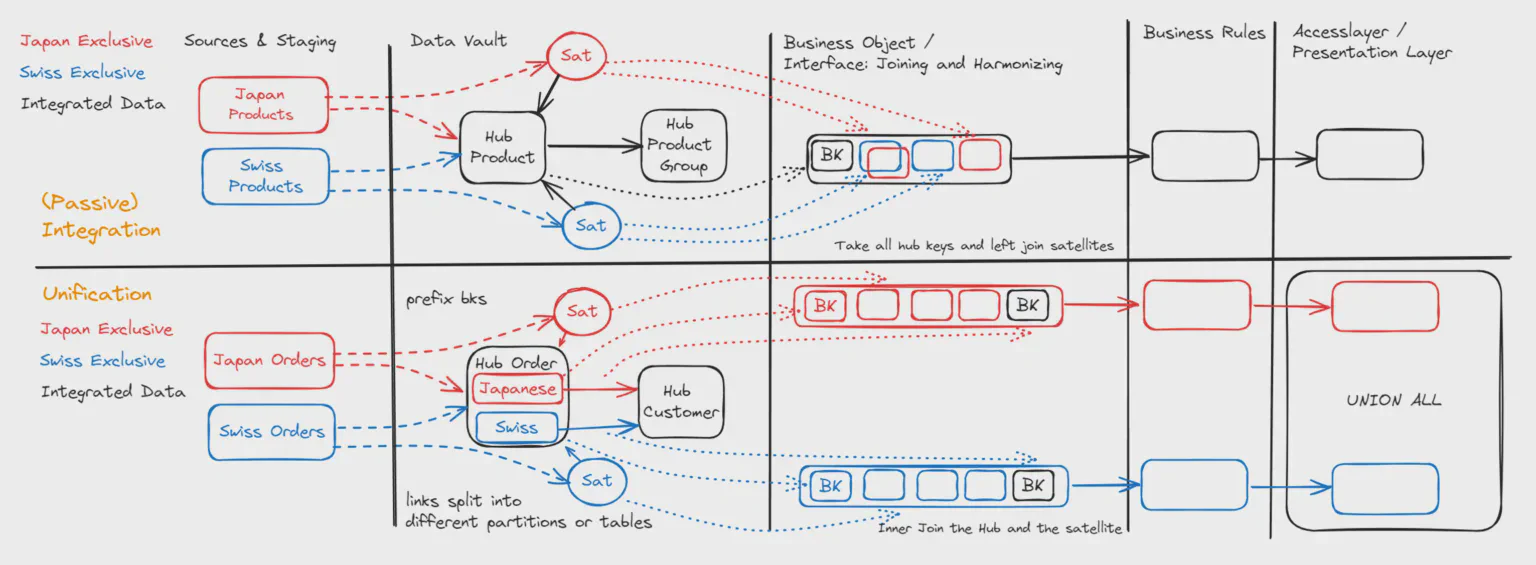
Aussi appelée intégration passive : nous avons deux systèmes sources différents avec la même clé métier. Un exemple que je vois souvent est le Produit avec le Numéro de Produit, qui est partagé plus ou moins efficacement entre différents systèmes.
Si nous voulons comparer le prix catalogue en Suisse et au Japon, nous pouvons charger les données ERP suisses et les données ERP japonaises dans le Hub Produit. Le Numéro de Produit est chargé sans préfixe dans le hub, et les attributs sont chargés dans un Satellite japonais et un Satellite suisse.
Si nous créons maintenant une interface de sortie au-dessus du Data Vault (dans Datavault Builder, nous appelons cela un « Business Object »), nous sélectionnerons toutes les clés du hub. Nous pouvons ensuite mettre le prix catalogue suisse dans une colonne et le prix catalogue japonais dans une autre.
Si le prix catalogue suisse est le maître mais qu’il existe certains produits exclusifs au Japon, nous pourrions créer une troisième colonne avec des règles de priorisation comme : si le prix suisse est rempli, prendre celui-ci ; si le prix catalogue suisse est vide, sélectionner le japonais. C’est le cas d’usage que nous, du moins moi, avons habituellement en tête lorsque nous démarrons un projet Data Vault.

Alors pourquoi avons-nous besoin de différencier l’Unionnement ? Il diffère en ce que les ensembles de données provenant de deux sources différentes sont non chevauchants / exclusifs. Un exemple courant est le Hub des Commandes. Les commandes de Suisse et du Japon sont unionnées dans ce hub, mais le Numéro de Commande 101 peut exister à la fois en Suisse et au Japon, sans qu’il s’agisse de la même commande par définition métier.
Cela signifie que
-
nous devons préfixer nos numéros de commande pour garder les ensembles de données séparés, et
-
nous n’avons pas besoin d’investir de la puissance de calcul pour essayer de combiner les commandes des deux systèmes sources avec une magie ingénieuse
-
nous pouvons garder les données séparées jusqu’à la couche de présentation, réduisant la quantité de données à joindre
-
nous pouvons paralléliser entièrement le traitement de ces deux flux de données lors du chargement dans le Data Vault
-
nous pouvons paralléliser entièrement lors de la sélection des données depuis le Data Vault
Le point positif est qu’habituellement, les grands ensembles de données sont en Unionnement, pas en Intégration.
Si nous acceptons une catégorie générale de Hubs en Unionnement comme un pattern à part entière :
-
Nous devons préfixer les clés métier pour les chargements du hub car il peut y avoir des plages de numéros (valeurs) qui se chevauchent et ne signifient pas la même chose.
-
Nous pouvons créer des tables de liens partitionnées par système (ou des tables de liens séparées). Cela permet de les charger en parallèle
-
Cela permet de les lire plus efficacement car le nombre de lignes jointes est réduit pour chaque système source, et cette réduction est exponentielle par rapport au nombre de systèmes sources.
-
La sortie peut être préparée séparément. L’harmonisation des noms de colonnes peut être faite virtuellement au niveau de chaque système.
-
Les règles métier peuvent être traitées au niveau de chaque système.
-
Création de la sortie unionnée : à la fin, nous pouvons utiliser une instruction UNION ALL générée pour combiner les ensembles de données des différentes sources.
-
Cela permet à la base de données de paralléliser la sélection des différents ensembles de données sources et aussi de pousser les filtres sur des ensembles de données spécifiques jusqu’au Data Vault.
Cela permet une préparation plus rapide de l’ensemble complet de données mais permet aussi de filtrer sur des systèmes séparés et de pousser également les filtres sur des colonnes de satellite spécifiques.
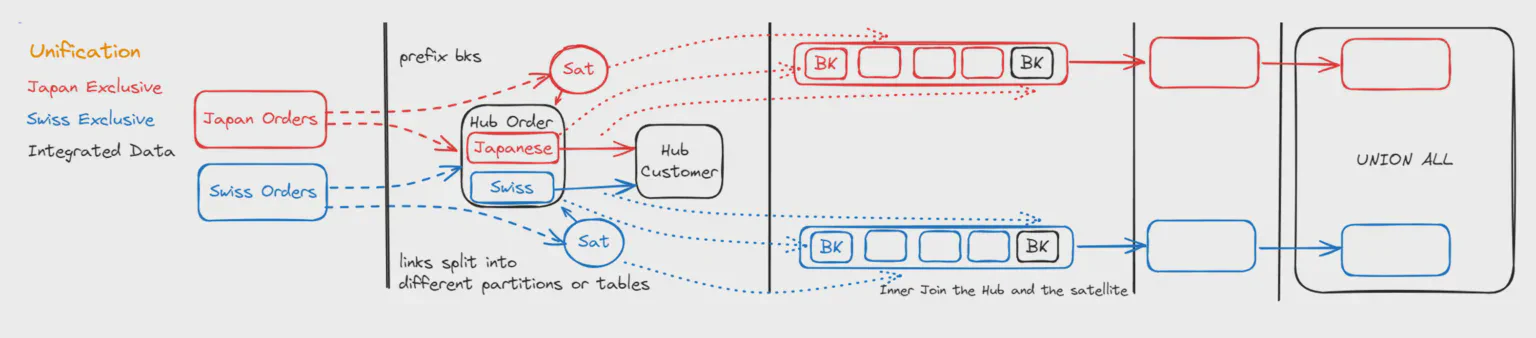
En différenciant Intégration et Unionnement, nous pouvons optimiser les patterns pour les entités à grands volumes de données. De plus, exprimer cette information dans notre modèle de données clarifie le but du pipeline d’intégration des données et aide à déterminer quels objets peuvent être joints pour produire une sortie significative.
Comment automatiser Intégration et Unionnement
Vous pouvez voir dans la vidéo suivante comment ces deux cas d’usage sont configurés entièrement automatiquement dans Datavault Builder :
Voir Datavault Builder en action
Démo de 20 minutes. Réponses honnêtes sur l'adéquation avec votre équipe.
Réserver une démo gratuite