Integrace a sjednocování dat
V Data Vault modelování používáme huby pro integraci dat. Je to jeden z hlavních důvodů, proč si Data Vault modelování vybíráme.
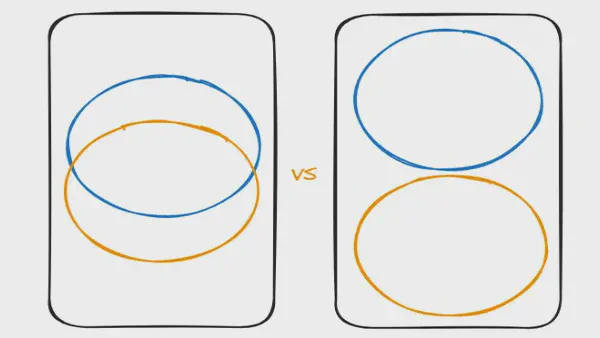
Sjednocování versus integrace hubů — proč na tom záleží V Data Vault modelování používáme huby pro integraci dat. To každý ví. Je to jeden z hlavních důvodů, proč si Data Vault modelování vybíráme: integrovat data z různých zdrojů. Ale co znamená „integrace"? Doposud jsem neviděl diskuzi o tom, jak data ve skutečnosti integrujeme.
V tomto článku zjednoduším své příklady s vědomím, že realita může být složitější než to, co je zde prezentováno. Pro stanovení hlavního konceptu by však mělo pomoci ponechat věci jednoduché.
V diskuzích s Carstenem Schweigerem jsme identifikovali dva různé patterny: Integraci a Sjednocování.
Integrace vs. Sjednocování
Toto rozlišení je důležité, protože mění, jak můžeme data optimálně zpracovávat. Pojďme tyto dvě možnosti popsat:
Integrace
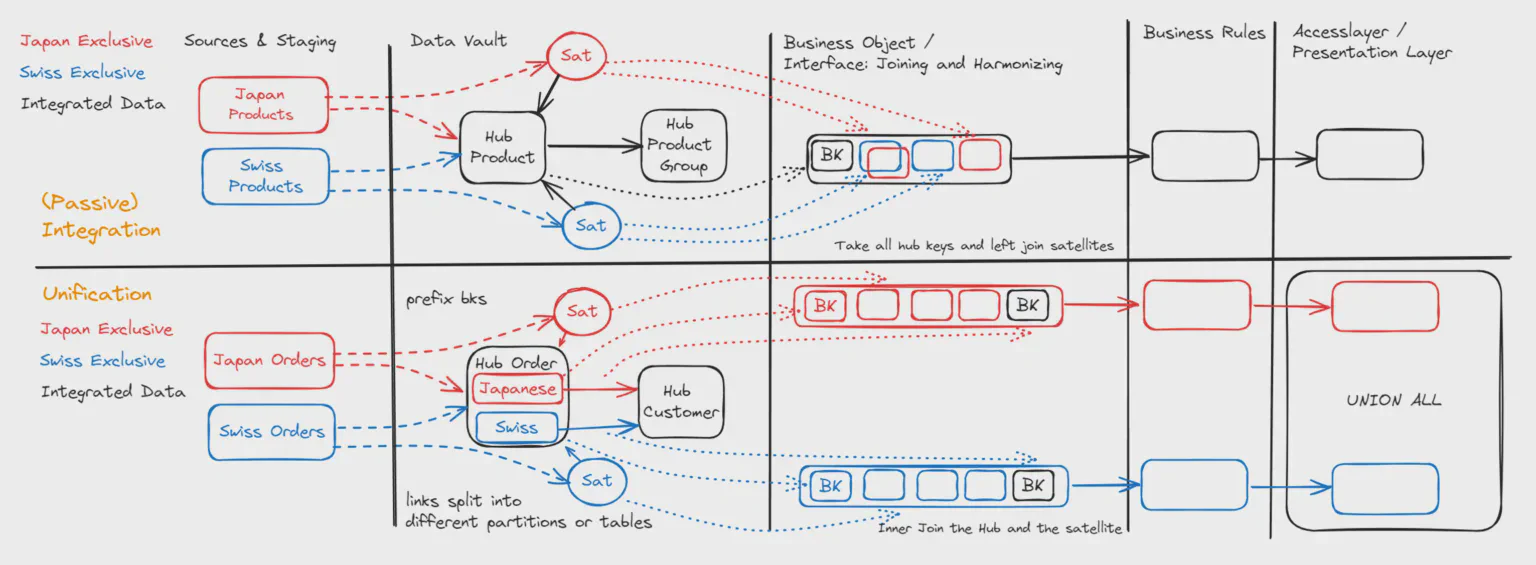
Také nazývaná pasivní integrace: máme dva různé zdrojové systémy se stejným byznysovým klíčem. Příklad, který často vidím, je Produkt s Číslem produktu, které je s různou mírou úspěšnosti sdíleno mezi různými systémy.
Pokud chceme porovnat ceníkovou cenu ve Švýcarsku a v Japonsku, můžeme načíst data ze švýcarského ERP a z japonského ERP do Hubu Produkt. Číslo produktu je do hubu načteno bez prefixu a atributy jsou načteny do japonského a švýcarského Satelitu.
Pokud nyní vytvoříme výstupní rozhraní nad Data Vaultem (v Datavault Builderu tomu říkáme „Business Object"), vybereme všechny klíče z hubu. Pak můžeme dát švýcarskou ceníkovou cenu do jednoho sloupce a japonskou ceníkovou cenu do druhého sloupce.
Pokud je švýcarská ceníková cena master, ale existují některé produkty exkluzivní pro Japonsko, mohli bychom vytvořit třetí sloupec s prioritizačními pravidly typu: pokud je švýcarská cena vyplněná, vezmi tu; pokud je švýcarská ceníková cena prázdná, vyber japonskou. Toto je případ užití, který my, alespoň já, obvykle máme na mysli, když začínáme Data Vault projekt.

Proč tedy potřebujeme rozlišovat Sjednocování? Liší se tím, že datové sady přicházející ze dvou různých zdrojů se nepřekrývají / jsou exkluzivní. Běžným příkladem je Hub Objednávek. Objednávky ze Švýcarska a Japonska se v tomto hubu sjednocují, ale Objednávka číslo 101 může existovat jak ve Švýcarsku, tak v Japonsku, ačkoli to není ta samá objednávka podle byznysové definice.
To znamená, že
-
musíme prefixovat naše čísla objednávek, aby zůstaly datové sady oddělené, a
-
nemusíme investovat výpočetní výkon do snahy zkombinovat objednávky ze dvou zdrojových systémů pomocí důmyslné magie
-
můžeme držet data oddělená až do prezentační vrstvy a tím snížit množství dat, která je třeba spojovat
-
můžeme plně paralelizovat zpracování těchto dvou datových toků při načítání do Data Vaultu
-
můžeme plně paralelizovat při výběru dat z Data Vaultu
Dobrá zpráva je, že obvykle jsou velké datové sady ve Sjednocování, ne v Integraci.
Pokud přijmeme obecnou kategorii Sjednocujících Hubů jako vlastní pattern:
-
Pro načítání hubu musíme prefixovat byznysové klíče, protože se mohou objevit překrývající se rozsahy čísel (hodnot), které neznamenají totéž.
-
Můžeme vytvořit linkové tabulky particionované podle systému (nebo oddělené linkové tabulky). To umožňuje jejich paralelní načítání
-
To umožňuje jejich efektivnější čtení, protože počet spojovaných řádků se snižuje pro každý zdrojový systém, a toto snížení je exponenciální vůči počtu zdrojových systémů.
-
Výstup lze připravit odděleně. Harmonizaci názvů sloupců lze provádět virtuálně na bázi jednotlivých systémů.
-
Byznysová pravidla lze zpracovávat na bázi jednotlivých systémů.
-
Vytvoření sjednoceného výstupu: nakonec můžeme použít vygenerovaný UNION ALL příkaz pro zkombinování datových sad z různých zdrojů.
-
To umožňuje databázi paralelizovat výběr různých zdrojových datových sad a také push-down filtrů na konkrétní datové sady směrem k Data Vaultu.
To umožňuje rychlejší přípravu kompletní datové sady, ale umožňuje také filtrování na oddělených systémech a push-down filtrů na konkrétní sloupce satelitů.
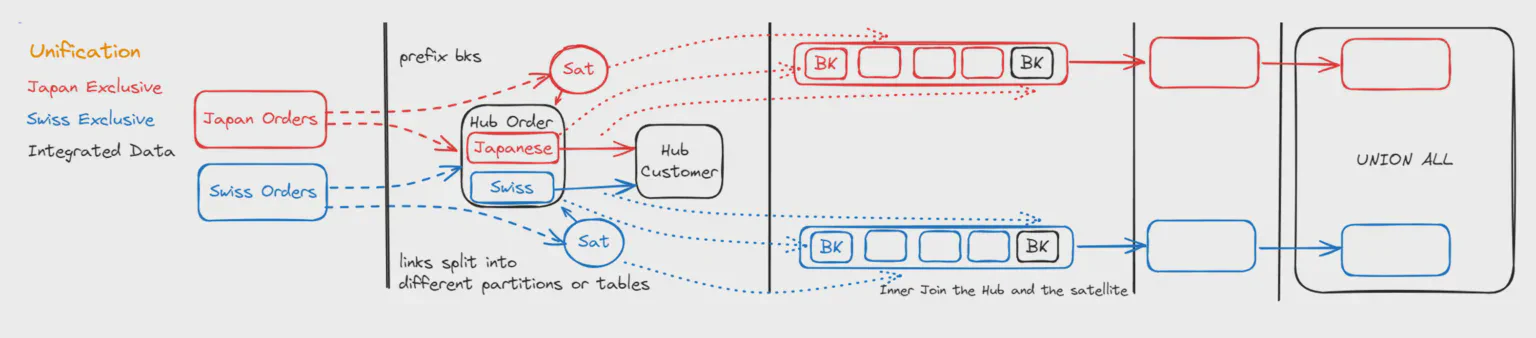
Rozlišením mezi Integrací a Sjednocováním můžeme optimalizovat patterny pro entity s velkými objemy dat. Vyjádření této informace v našem datovém modelu navíc objasňuje účel datové integrační pipeline a pomáhá určit, které objekty lze spojit pro smysluplný výstup.
Jak automatizovat Integraci a Sjednocování
V následujícím videu uvidíte, jak se tyto dva případy užití konfigurují plně automaticky v Datavault Builderu:
Vyzkoušejte Datavault Builder v akci
Živé demo. Upřímné odpovědi, zda je to pro váš tým.
Rezervovat bezplatné demo