Integrar y unificar datos
En el modelado Data Vault usamos hubs para integrar datos. Es una de las principales razones por las que elegimos el modelado Data Vault.
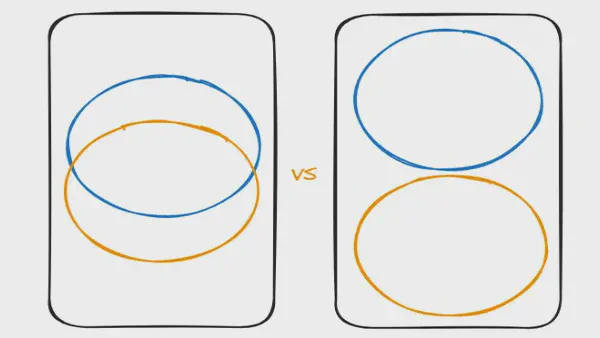
Unificar versus integrar hubs — por qué importa En el modelado Data Vault, usamos hubs para integrar datos. Todo el mundo lo sabe. Es una de las principales razones por las que elegimos el modelado Data Vault: integrar datos de diversas fuentes. Pero ¿qué significa «integración»? Hasta ahora no he visto una discusión sobre cómo integramos realmente los datos.
En este artículo simplificaré mis ejemplos, sabiendo que la realidad puede ser más compleja de lo que aquí se presenta. No obstante, para establecer el concepto principal, simplificar debería ayudar.
En conversaciones con Carsten Schweiger hemos identificado dos patrones diferentes: Integración y Unificación.
Integración vs. Unificación
Esta distinción es importante porque cambia la forma en que podemos procesar los datos de manera óptima. Caractericemos las dos opciones:
Integración
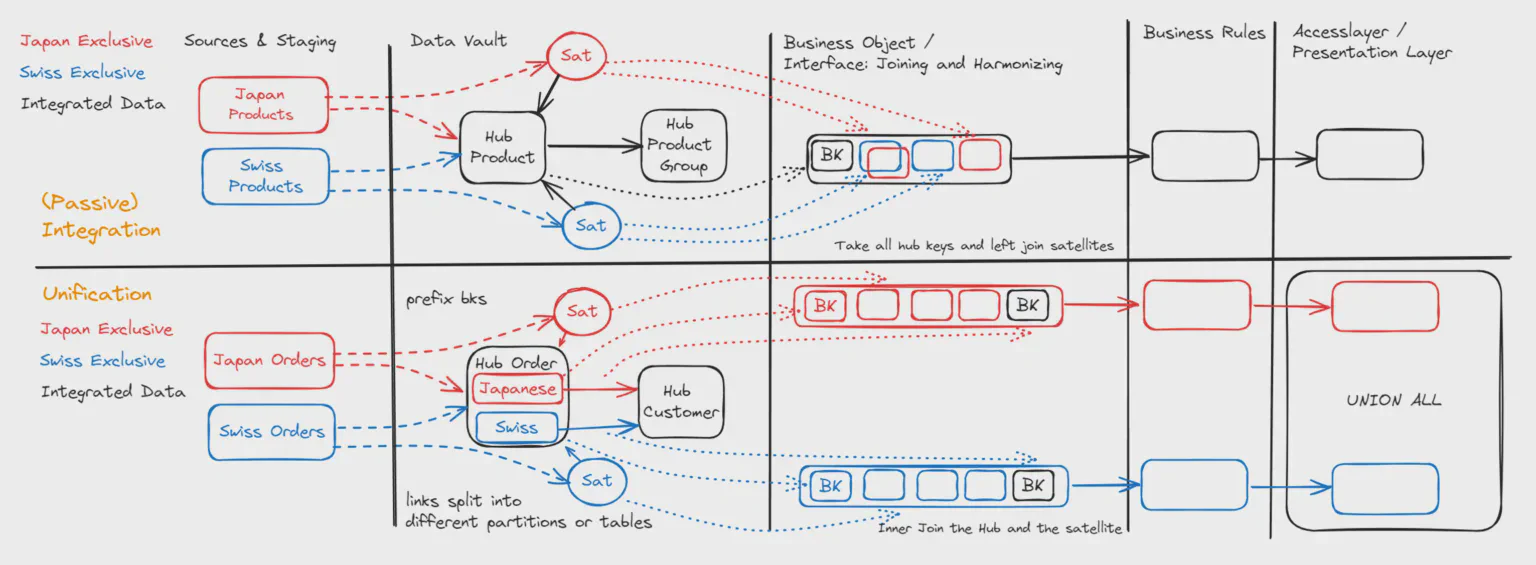
También llamada integración pasiva: tenemos dos sistemas origen distintos con la misma clave de negocio. Un ejemplo que veo a menudo es el Producto con el Número de Producto, que se comparte con mayor o menor éxito entre distintos sistemas.
Si queremos comparar el precio de lista en Suiza y en Japón, podemos cargar los datos del ERP suizo y del ERP japonés en el Hub Producto. El Número de Producto se carga sin prefijo en el hub, y los atributos se cargan en un Satélite japonés y un Satélite suizo.
Si ahora creamos una interfaz de salida sobre el Data Vault (en Datavault Builder lo llamamos un «Business Object»), seleccionaremos todas las claves del hub. Podemos entonces poner el precio de lista suizo en una columna y el precio de lista japonés en otra.
Si el precio de lista suizo es el maestro pero hay algunos productos exclusivos de Japón, podríamos crear una tercera columna con reglas de priorización como: si el precio suizo está relleno, tomar ese; si el precio de lista suizo está vacío, seleccionar el japonés. Este es el caso de uso que nosotros, al menos yo, solemos tener en mente cuando empezamos un proyecto Data Vault.

¿Por qué entonces necesitamos diferenciar la Unificación? Difiere en que los conjuntos de datos provenientes de dos fuentes distintas no se solapan / son exclusivos. Un ejemplo común es el Hub de Pedidos. Los pedidos de Suiza y de Japón se unifican en este hub, pero el Pedido número 101 puede existir tanto en Suiza como en Japón, sin que sea el mismo pedido por definición de negocio.
Esto significa que
-
necesitamos prefijar nuestros números de pedido para mantener los conjuntos de datos separados, y
-
no necesitamos invertir potencia de cómputo para intentar combinar pedidos de los dos sistemas origen con magia ingeniosa
-
podemos mantener los datos separados hasta la capa de presentación, reduciendo la cantidad de datos a juntar
-
podemos paralelizar completamente el procesamiento de estos dos flujos de datos al cargar en el Data Vault
-
podemos paralelizar completamente al seleccionar datos del Data Vault
Lo bueno es que normalmente los grandes conjuntos de datos son de Unificación, no de Integración.
Si aceptamos una categoría general de Hubs de Unificación como un patrón propio:
-
Necesitamos prefijar las claves de negocio para las cargas del hub, ya que pueden existir rangos de números (valores) solapados que no significan lo mismo.
-
Podemos crear tablas de links particionadas por sistema (o tablas de links separadas). Esto permite cargarlas en paralelo
-
Esto permite leerlas de forma más eficiente porque el número de filas juntadas se reduce por cada sistema origen, y esta reducción es exponencial respecto al número de sistemas origen.
-
La salida puede prepararse por separado. La armonización de nombres de columnas puede hacerse virtualmente por sistema.
-
Las reglas de negocio pueden procesarse por sistema.
-
Crear la salida unificada: al final podemos usar una sentencia UNION ALL generada para combinar los conjuntos de datos de las distintas fuentes.
-
Esto permite a la base de datos paralelizar la selección de los distintos conjuntos de datos origen y también enviar filtros sobre conjuntos específicos hasta el Data Vault.
Esto permite una preparación más rápida del conjunto completo de datos pero también filtrar por sistemas separados y enviar filtros sobre columnas concretas de satélite.
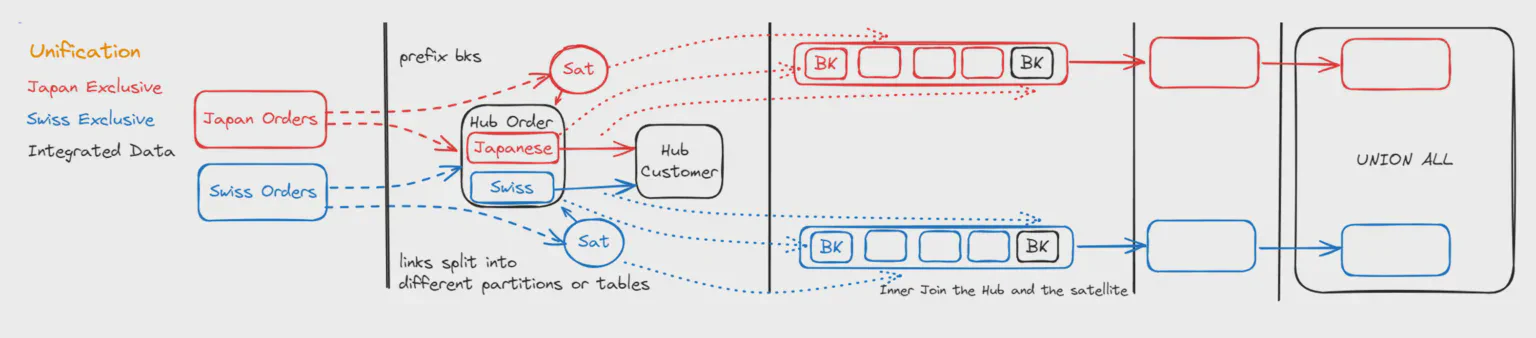
Diferenciando entre Integración y Unificación podemos optimizar los patrones para entidades con grandes volúmenes de datos. Además, expresar esta información en nuestro modelo de datos clarifica el propósito de la pipeline de integración y ayuda a determinar qué objetos pueden juntarse para una salida significativa.
Cómo automatizar Integración y Unificación
Puede ver en el siguiente vídeo cómo estos dos casos de uso se configuran de forma totalmente automática en Datavault Builder:
Vea Datavault Builder en acción
Demo en vivo. Respuestas honestas sobre si encaja con su equipo.
Reservar una Demo Gratuita