Data Vault bi-temporel : Inscription Time
Comment charger des données bi-temporelles dans le Data Vault en utilisant l'Inscription Time — patterns, pièges et exemples pratiques.
Par exemple : comment résoudre le problème de la posting-date dans les banques
Un défi que nous rencontrons souvent en travaillant avec des clients de la banque et de l’assurance est la donnée qui possède déjà une ou plusieurs timelines.
Je distingue ici trois timelines principales. Je sais que dans l’assurance il peut y avoir 6 timelines ou plus, mais commençons par les « bases ».
Comme nous travaillons principalement avec des systèmes IT comme source de nos données : une timeline qui existe toujours est l’inscription timeline. Pour moi, c’est le moment où l’information a été capturée dans le système source.
Pour certaines données, c’est tout. Elles ne seront jamais transférées vers un DWH et n’ont aucune prétention sur le passé ou le futur. Super : vous avez fini.
Mais dans notre cas, ces données sont transférées vers votre DWH. Supposons que vous utilisiez Data Vault comme paradigme de conception (mais cela s’appliquerait à toutes les autres techniques de modélisation conscientes du temps — non, Data Mesh n’est pas une approche de modélisation mais un paradigme organisationnel). Charger les données dans vos hubs, links et satellites ajoute ce qu’on appelle une « Load Date » (qui est, c’est drôle, espérons-le, un timestamp). Notez que je n’utilise pas « valid from » ou « valid to » dans ce contexte, car cela pousse les gens à confondre cette timeline avec la validité métier.
Si vous chargez ces données à une cadence hebdomadaire, quotidienne ou même horaire et ne prenez que la dernière information du système source, l’ensemble reste simple car vous n’ajoutez qu’une seule timeline supplémentaire. Votre automatisation Data Vault garde tout en mémoire, présentant idéalement l’information as-of-now et as-of-then sur demande.
Honnêtement : nous avons beaucoup de clients qui n’ont pas plus que ce niveau de complexité, et ils devraient s’arrêter de lire ici. Cependant, je recommande de lire ma série sur la temporalité dans le Data Vault pour de tels cas d’usage.
Si vous avez aussi une validité métier capturée dans votre système source, lire mes précédents posts est judicieux pour apprendre à stocker cette information en étendant la clé du hub.
En supposant que la timeline d’inscription soit très pertinente pour vous, ignorez le conseil de mes précédentes entrées de blog selon lequel l’inscription time peut être ignoré si le load time est juste assez proche.
Exemples où l’inscription time est pertinent :
· Vous obtenez des changements à très haute cadence, et vos chargements DWH sont moins fréquents, et tous ces changements sont pertinents pour vous — soit parce qu’ils ont une valeur métier, soit parce qu’il faut les tracer pour l’auditabilité — votre source d’information sera très probablement un flux Change Data Capture (CDC).
· Votre source n’est pas le système source lui-même mais une forme d’export, et il arrive que ce type d’export contienne des erreurs, des données incomplètes, ou les deux.
· L’inscription time est la timeline plus précise pour votre reporting que votre load time — comme les données basées sur la posting time (aussi appelée Tages-End-Verarbeitung (TEV), COB, EOB) qui représentent la « vraie » histoire.
Formulons-le différemment : si l’inscription time est pertinent pour vous, vous le savez généralement.
Approche-Solution : rendre l’inscription time non pertinent
Si vous réduisez le temps entre l’inscription dans le système source et le chargement dans le Data Vault, vous pouvez ignorer l’Inscription Time dans presque tous les cas et vous appuyer sur le Load Time SI vos données arrivent dans l’ordre. Dans le cas d’un flux Kafka, par exemple, ce n’est pas le cas. Si les données arrivent hors ordre, cette approche générerait une sortie complètement fausse.
Approche-Solution 1 : Créer une couche Persistent Staging
En utilisant vos patterns Data Vault par défaut, vous pouvez prendre votre change key, qui peut être la clé technique plus l’inscription time ou une change key livrée par le flux CDC, et stocker d’abord tous les changements dans votre persistent staging area (PSA). Puis créer la dernière vue par-dessus et la charger dans le Raw Vault. Cela vous rendra entièrement auditable car vous gardez toutes les informations dans la PSA.
La limitation est que l’image du Raw Vault n’est mise à jour qu’à vos intervalles de chargement si vous ne créez pas de pattern de chargement personnalisé. Cela signifie que si les changements se produisent à l’échelle de la seconde ou de la microseconde, ils sont stockés dans la PSA mais pas dans le Raw Vault s’ils ne créent pas de boucles pour charger chaque enregistrement vers le vault.
Le vrai problème est que même en créant des boucles pour charger le vault : si vous obtenez des valeurs corrigées ou hors ordre pour le passé, vous ne pouvez pas les insérer au bon endroit dans votre satellite Raw Vault. Donc, s’il y a la moindre chance pour un tel scénario et que cela doit être capturé, c’est rédhibitoire.
Approche-Solution 2 : Inscription time comme Load Time
Je suis toujours pour réduire la complexité, alors pourquoi ne pas envisager de charger votre inscription time directement dans vos colonnes de load time ? Cela semble être une bonne idée. Simple à implémenter. Vous n’avez pas besoin de changer les structures de vos tables Data Vault et tous les outils au-dessus continuent de fonctionner.
En théorie, cela pourrait être une bonne solution si vous supposez que les données que vous recevez sont toujours correctes et ne seront jamais corrigées par la suite. C’est vraiment une mauvaise hypothèse :
Dans le cas d’exports qui vous sont livrés, il y aura toujours des corrections.
Même les flux CDC : s’ils sont interrompus, vous pourriez resynchroniser le statut de la table de base avec vos données actuellement chargées.
· Les informations de posting date sont parfois aussi livrées hors synchronisation
Et dès que vous recevez des informations différentes pour le même inscription time, vous devriez supprimer l’information déjà chargée. Ou la déplacer vers une table d’archive. Ou faire d’autres choses peu élégantes.
En bref : même si cela pourrait être une solution dans un scénario très limité, il y a de fortes chances qu’à un moment ou un autre vous tombiez sur des cas où l’information stockée est, dans le meilleur des cas, incomplète, ou dans le pire, fausse.
Approche-Solution 3 : Satellites bi-temporels
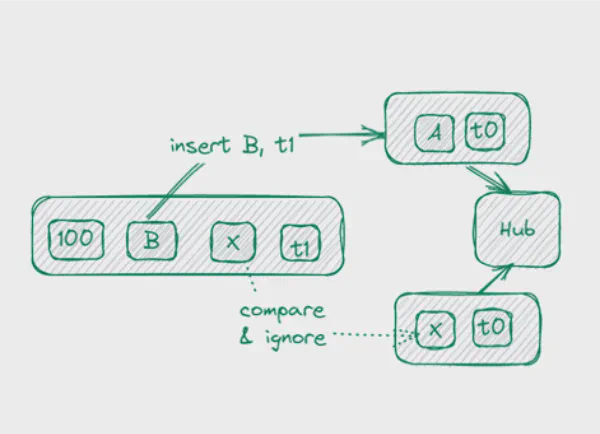
L’approche correcte est d’utiliser un multi-active satellite en étendant la clé du satellite pour inclure hash-key (HK), load-time et inscription time.
Lors du chargement des données, nous comparons maintenant le HK et l’inscription time des données stagées avec les données dans le vault, et si les attributs sont différents ou si l’entrée est manquante, nous l’insérons simplement avec le timestamp courant comme load time.
L’avantage : nous pouvons toujours utiliser le pattern insert-only pour charger le satellite.
Inconvénient : nous avons maintenant un historique bi-temporel à l’intérieur. Si quelque chose arrive hors ordre, c’est OK. Nous composerons les connaissances actuelles sur l’historique uniquement au moment de la lecture.
Mais c’est un problème lors de la requête sur ces données. Cela peut être résolu en utilisant des fonctions analytiques pour partitionner soit par « hash & inscription time », soit uniquement par « hash ».
L’inconvénient est que la performance peut devenir mauvaise si vous joignez différentes requêtes utilisant chacune une fonction analytique. Mais comme dit Markus Winand : « Use the index Luke ! ». C’est ce que fait une PIT table.
Heureusement, Patrick Cuba a écrit un article intéressant sur l’utilisation des séquences pour créer des PIT tables plus compactes.
Cette solution s’inscrit-elle dans le framework DV2.0 ? Je dirais : oui. Le satellite bi-temporel est une forme spéciale du multi-active satellite.
Compression
On pourrait supposer qu’un flux CDC ne livre que des changements pertinents. En réalité, ce n’est pas toujours le cas. Mais même si c’est le cas : dès que vous commencez à diviser les données dans différents satellites, il y aura des lignes CDC qui ne provoquent pas de changement dans un satellite donné. Nous devons donc appliquer la compression.
Arrivée hors ordre combinée à la compression
Mais dès que vous obtenez des données redélivrées pour un inscription time plus ancien, cela peut causer de graves problèmes si vous ignorez les lignes pour certains satellites parce qu’elles ne contenaient aucune nouvelle information. Si plus tard une information est livrée pour un inscription time plus ancien, elle pourrait causer des données erronées. C’est pourquoi nous devons garder trace de toutes les informations compressées dans le tracking satellite.
Voici un exemple où aux instants t0, t1 et t2 la valeur « a » a été livrée et compressée. Maintenant, à un load time ultérieur, pour l’inscription time t1, la valeur « c » est livrée. Cette valeur sera insérée à inscription t1 dans le satellite ET aussi à inscription time t2 la valeur « a » qui était précédemment compressée doit maintenant être insérée car elle diffère de la valeur « c » à t1.
Pour nos lecteurs germanophones, nous avons une vidéo disponible :
Et maintenant ? Dois-je m’occuper de l’inscription time ?
Mais Petr, tu prêchais toujours d’ignorer les inscription times ; pourquoi écris-tu maintenant sur la façon de les stocker et de les évaluer ?
Premièrement : j’ai toujours précisé sous quelles conditions vous pouvez ignorer l’inscription time.
Deuxièmement : la plupart d’entre vous devraient quand même ignorer l’inscription time dans la plupart des cas.
Troisièmement : j’ai commencé ma carrière dans la banque, donc je comprends la nécessité de tels patterns.
Mais maintenant, avec une base clients croissante pour notre logiciel Datavault Builder, nous avons reçu de plus en plus de demandes pour une solution générale et après de longues sessions de design et de prototype ces derniers mois, nous avons conclu que seul le satellite bi-temporel résout correctement le problème, et c’est ce que nous avons fait et publié dans la version 6.3 de Datavault Builder.
Bravo à Patrick Cuba (Snowpit) et Thomas Herzog (idée générale des satellites bi-temporels comme type spécial de multi-active satellites) et Dirk Lerner (tous ses documents sur la Multi-Temporalité).
Voir Datavault Builder en action
Démo de 20 minutes. Réponses honnêtes sur l'adéquation avec votre équipe.
Réserver une démo gratuite