Data Vault bi-temporal: Inscription Time
Cómo cargar datos bi-temporales en el Data Vault usando Inscription Time — patrones, trampas y ejemplos prácticos.
Como ejemplo: cómo resolver el problema de la posting date en bancos
Un reto que encontramos a menudo trabajando con clientes de banca y seguros son los datos que ya tienen una o varias timelines asociadas.
Aquí me gusta diferenciar tres timelines principales. Sé que en el negocio asegurador puede haber 6 o más timelines, pero empecemos con lo «básico».
Como trabajamos principalmente con sistemas IT como origen de datos: una timeline que siempre existe es la timeline de inscripción. Para mí es el momento en que la información fue capturada en el sistema origen.
Y para algunos datos, eso es todo. Nunca se transferirán a un DWH y no hacen ninguna afirmación sobre el pasado o el futuro. Genial: ha terminado.
Pero en nuestro caso, estos datos se transfieren a su DWH. Asumamos que usa Data Vault como paradigma de diseño (pero esto se aplicaría a todas las demás técnicas de modelado conscientes del tiempo — no, Data Mesh no es un paradigma de modelado sino organizacional). Cargar los datos en sus hubs, links y satélites añade lo que se llama una «Load Date» (que, qué gracioso, esperemos que sea un timestamp). Note que no uso «valid from» o «valid to» en este contexto, porque hace que la gente confunda esta timeline con la validez de negocio.
Si carga estos datos con cadencia semanal, diaria o incluso horaria y solo toma la última información del sistema origen, todo se mantiene simple ya que solo añade una timeline más. Su automatización Data Vault realiza el seguimiento de todo, idealmente presentando la información as-of-now y as-of-then bajo demanda.
Honestamente: tenemos muchos clientes que no van más allá de este nivel de complejidad y deberían dejar de leer aquí. Aun así, recomiendo leer mi serie sobre temporalidad en el Data Vault para tales casos de uso.
Si también tiene una validez de negocio capturada dentro de su sistema origen, leer mis posts anteriores tiene sentido para aprender a almacenar esta información extendiendo la clave del hub.
Asumiendo que la timeline de inscripción es muy relevante para usted, ignore el consejo en mis entradas anteriores de blog que dice que el inscription time se puede ignorar si el load time está lo suficientemente cerca.
Ejemplos en los que el inscription time es relevante:
· Recibe cambios con muy alta cadencia, sus cargas DWH ocurren con menos frecuencia, y todos esos cambios son relevantes — bien por valor de negocio o por requerirse para auditabilidad — muy probablemente su origen de información será un stream Change Data Capture (CDC).
· Su origen no es el sistema origen mismo sino algún tipo de export, y a veces ese export contiene errores, datos incompletos, o ambos.
· El inscription time es la timeline más precisa para su reporting que el load time — como datos basados en posting time (también llamado Tages-End-Verarbeitung (TEV), COB, EOB) que representan la «verdadera» historia.
Formulémoslo de otra forma: si el inscription time es relevante para usted, normalmente lo sabrá.
Enfoque-Solución: hacer irrelevante el inscription time
Si reduce el tiempo entre la inscripción en el sistema origen y la carga en el Data Vault, puede ignorar el Inscription Time en casi cualquier caso y confiar en el Load Time SI sus datos llegan en orden. En el caso de un stream Kafka, por ejemplo, no es así. Si los datos llegan fuera de orden, este enfoque generaría una salida completamente incorrecta.
Enfoque-Solución 1: Crear una capa Persistent Staging
Usando sus patrones Data Vault por defecto, puede tomar su change key, que podría ser la clave técnica más el inscription time o una change key entregada por el stream CDC, y primero almacenar todos los cambios en su persistent staging area (PSA). Luego cree la última vista por encima y cárguelo en el Raw Vault. Esto le hará totalmente auditable porque mantiene toda la información en la PSA.
La limitación es que la imagen del Raw Vault solo se actualiza en sus intervalos de carga si no crea un patrón de carga personalizado. Esto significa que si los cambios ocurren en el área de segundos o microsegundos, se almacenan en la PSA pero no en el Raw Vault si no crean bucles para cargar todos y cada uno de los registros al vault.
El verdadero problema es que incluso creando bucles para cargar el vault: si recibe valores corregidos o fuera de orden para el pasado, no puede ordenarlos en el lugar correcto en su satélite Raw Vault. Por tanto, si hay la mínima posibilidad de tal escenario y necesita capturarse, eso es un deal breaker.
Enfoque-Solución 2: Inscription time como Load Time
Siempre soy partidario de reducir la complejidad, así que ¿por qué no pensar en cargar su inscription time directamente en sus columnas de load time? Suena como una buena idea. Sencillo de implementar. No necesita cambiar las estructuras de sus tablas Data Vault y todas las herramientas por encima siguen funcionando.
En teoría, esto podría ser una buena solución si asume que los datos que recibe siempre son correctos y nunca serán corregidos después. Es realmente una mala suposición:
En el caso de exports entregados a usted, siempre habrá correcciones.
Incluso los streams CDC: si se interrumpen, podría sincronizar el estado de la tabla base con sus datos cargados actualmente.
· La información de posting date también se entrega a veces fuera de sincronización
Y tan pronto como reciba información distinta para el mismo inscription time, tendría que eliminar la información ya cargada. O moverla a alguna tabla de archivo. O hacer alguna otra fea cosa.
En resumen: aunque podría ser una solución en un escenario muy limitado, la probabilidad es alta de que tarde o temprano se tope con casos donde la información que almacena es, en el mejor caso, incompleta, o errónea en el peor.
Enfoque-Solución 3: Satélites bi-temporales
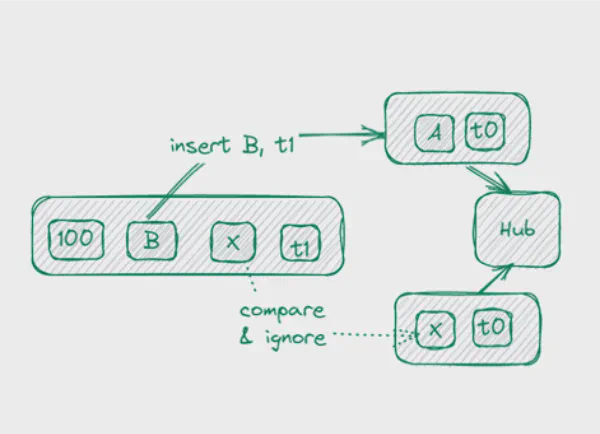
El enfoque correcto es usar un multi-active satellite extendiendo la clave en el satélite para incluir hash-key (HK), load-time e inscription time.
Al cargar datos, ahora comparamos el HK e inscription time de los datos stageados contra los datos del vault, y si los atributos son distintos o la entrada falta, simplemente la insertamos con el timestamp actual como load time.
La ventaja: aún podemos usar el patrón insert-only para cargar el satélite.
Desventaja: ahora tenemos historia bi-temporal dentro. Si algo llega fuera de orden, está bien. Compondremos el conocimiento actual sobre la historia solo en tiempo de lectura.
Pero eso es un problema al consultar esos datos. Esto puede resolverse usando funciones analíticas para particionar por «hash & inscription time» o solo por «hash».
La desventaja es que el rendimiento puede empeorar si une distintas consultas, cada una usando una función analítica. Pero como dice Markus Winand: «Use the index Luke!». Eso es lo que hace una PIT table.
Afortunadamente, Patrick Cuba escribió un artículo interesante sobre cómo usar secuencias para crear PIT tables más compactas.
¿Encaja la solución en el framework DV2.0? Diría que sí. El satélite bi-temporal es una forma especial del multi-active satellite.
Compresión
Podría suponer que un stream CDC solo entrega cambios relevantes. En la realidad eso no siempre es así. Pero incluso si ese es el caso: tan pronto como divide los datos en distintos satélites, habrá filas CDC que no causan un cambio en un satélite dado. Por tanto, necesitamos aplicar compresión.
Llegada fuera de orden combinada con compresión
Pero tan pronto como recibe datos reentregados para un inscription time más antiguo, puede causar problemas serios si ignora filas para ciertos satélites porque no contenían información nueva. Si más tarde se entrega información para un inscription time más antiguo, podría causar datos incorrectos. Por eso necesitamos llevar registro de toda la información comprimida en el tracking satellite.
Aquí un ejemplo donde en t0, t1 y t2 se entregó y comprimió el valor «a». Ahora, en un load time posterior para el inscription time t1, se entrega el valor «c». Este valor se insertará en inscription t1 en el satélite Y también en inscription time t2 el valor «a» que se comprimió antes necesita insertarse ahora porque es distinto del valor «c» en t1.
Para nuestros germanohablantes tenemos un vídeo disponible:
¿Y ahora? ¿Necesito ocuparme del inscription time?
Pero Petr, ¿siempre predicabas ignorar los inscription times; por qué ahora escribes sobre cómo almacenarlos y evaluarlos?
Primero: siempre especifiqué bajo qué condiciones se puede ignorar el inscription time.
Segundo: aun así, la mayoría debería ignorar el inscription time en la mayoría de los casos.
Tercero: empecé mi carrera en banca, así que entiendo la necesidad de tales patrones.
Pero ahora, con una base de clientes creciente para nuestro software Datavault Builder, recibimos cada vez más solicitudes de una solución general y, tras largas sesiones de diseño y prototipado en los últimos meses, concluimos que solo el satélite bi-temporal resuelve adecuadamente el problema, y eso es lo que hemos hecho y publicado en la versión 6.3 de Datavault Builder.
Reconocimientos a Patrick Cuba (Snowpit) y Thomas Herzog (idea general de los satélites bi-temporales como tipo especial de multi-active satellites) y Dirk Lerner (todos sus documentos sobre Multi-Temporalidad).
Vea Datavault Builder en acción
Demo en vivo. Respuestas honestas sobre si encaja con su equipo.
Reservar una Demo Gratuita