Data Vault bi-temporálně: Inscription Time
Jak načítat bi-temporální data do Data Vaultu pomocí Inscription Time — patterny, úskalí a praktické příklady.
Jako příklad: jak vyřešit problém posting date v bankách
Výzva, na kterou často narážíme při práci s klienty z bankovnictví a pojišťovnictví, jsou data, která už mají k sobě připojenu jednu nebo více timeline.
Rád zde rozlišuji tři hlavní timeline. Vím, že v pojišťovnictví může být 6 nebo více timeline, ale začněme „základy".
Jelikož pracujeme primárně s IT systémy jako zdrojem dat: timeline, která vždy existuje, je inscription timeline. Pro mě je to čas, kdy byla informace zachycena ve zdrojovém systému.
A pro některá data je to vše. Nikdy nebudou přenesena do DWH a nečiní si nárok na minulost ani budoucnost. Skvělé: máte hotovo.
V našem případě jsou ale tato data přenesena do vašeho DWH. Předpokládejme, že používáte Data Vault jako návrhové paradigma (ale platilo by to pro všechny ostatní časově citlivé modelovací techniky — ne, Data Mesh není modelovací, ale organizační paradigma). Načítání dat do vašich hubů, linků a satelitů přidává tzv. „Load Date" (což je vtipně, doufejme, časové razítko). Všimněte si, že v tomto kontextu nepoužívám „valid from" ani „valid to", protože to lidi nutí zaměňovat tuto timeline s byznysovou platností.
Pokud načítáte tato data s týdenní, denní nebo i hodinovou kadencí a berete jen poslední informaci ze zdrojového systému, vše zůstává jednoduché, protože přidáváte pouze jednu další timeline. Vaše Data Vault automatizace vše sleduje a v ideálním případě prezentuje informace as-of-now a as-of-then na požádání.
Upřímně: máme spoustu klientů, kteří nemají větší úroveň složitosti, a měli by zde přestat číst. Přesto doporučuji přečíst si pro takové případy mou sérii o temporalitě v Data Vaultu.
Pokud máte také byznysovou platnost zachycenou ve zdrojovém systému, je rozumné přečíst si mé předchozí příspěvky, abyste se naučili tuto informaci ukládat rozšířením klíče hubu.
Za předpokladu, že je inscription timeline pro vás velmi relevantní, ignorujte radu z mých předchozích příspěvků, že inscription time lze ignorovat, pokud je load time dost blízko.
Příklady, kdy je inscription time relevantní:
· Dostáváte změny ve velmi vysoké kadenci, vaše DWH načítání probíhají méně často a všechny tyto změny jsou pro vás relevantní — ať už mají byznysovou hodnotu, nebo je nutné je sledovat kvůli auditovatelnosti — vaším zdrojem informací bude pravděpodobně Change Data Capture (CDC) stream.
· Vaším zdrojem není zdrojový systém samotný, ale nějaká forma exportu, a stává se, že tento typ exportu obsahuje chyby, neúplná data, nebo obojí.
· Inscription time je přesnější timeline pro váš reporting než váš load time — jako data založená na posting time (také zvaná Tages-End-Verarbeitung (TEV), COB, EOB), která reprezentují „skutečnou" historii.
Řekněme to jinak: pokud je pro vás inscription time relevantní, obvykle to budete vědět.
Řešení-Přístup: učinit inscription time irelevantním
Pokud snížíte čas mezi inscription ve zdrojovém systému a načtením do Data Vaultu, můžete Inscription Time téměř v každém případě ignorovat a spolehnout se na Load Time, POKUD vaše data přicházejí v pořadí. V případě Kafka streamu tomu tak například není. Pokud data přicházejí mimo pořadí, tento přístup by generoval zcela špatný výstup.
Řešení-Přístup 1: Vytvoření vrstvy Persistent Staging
Pomocí svých výchozích Data Vault patternů můžete vzít svůj change key, kterým může být technický klíč plus inscription time nebo change key dodávaný CDC streamem, a nejprve uložit všechny změny do vašeho persistent staging area (PSA). Pak vytvořit nejnovější pohled nad ním a načíst ten do Raw Vaultu. Učiníte se plně auditovatelnými, protože v PSA udržujete všechny informace.
Omezením je, že obraz Raw Vaultu se aktualizuje pouze v intervalech vašeho načítání, pokud nevytvoříte vlastní pattern načítání. To znamená, že pokud změny probíhají v oblasti sekund nebo mikrosekund, jsou uloženy v PSA, ale ne v Raw Vaultu, pokud nevytvoříte smyčky pro načítání každého záznamu do vaultu.
Skutečným problémem je, že i při vytváření smyček pro načítání vaultu: pokud dostanete opravené nebo mimo-pořadí hodnoty pro minulost, nemůžete je v Raw Vault satelitu zařadit do správného místa. Takže pokud existuje byť jen malá šance pro takový scénář a je třeba ho zachytit, je to deal-breaker.
Řešení-Přístup 2: Inscription time jako Load Time
Vždy jsem pro snižování složitosti, tak proč nezvážit načítání inscription time přímo do sloupců load time? Zní to jako dobrý nápad. Snadno se implementuje. Nemusíte měnit strukturu Data Vault tabulek a všechny nástroje nad nimi pokračují fungovat.
Teoreticky by to mohlo být dobré řešení, pokud předpokládáte, že data, která dostáváte, jsou vždy správná a nikdy nebudou opravena později. To je opravdu špatný předpoklad:
V případě exportů dodávaných vám budou vždy opravy.
Dokonce i CDC streamy: pokud jsou přerušeny, můžete synchronizovat stav základní tabulky s vašimi aktuálně načtenými daty.
· Informace o posting date jsou někdy také dodávány mimo synchronizaci
A jakmile dostanete různé informace pro stejný inscription time, museli byste smazat již načtenou informaci. Nebo ji přesunout do nějaké archivní tabulky. Nebo dělat jiné nehezké věci.
Krátce: i když by to mohlo být řešení ve velmi omezeném scénáři, šance je vysoká, že dříve nebo později narazíte na případy, kdy informace, kterou ukládáte, je v lepším případě neúplná nebo v horším špatná.
Řešení-Přístup 3: Bi-temporální satelity
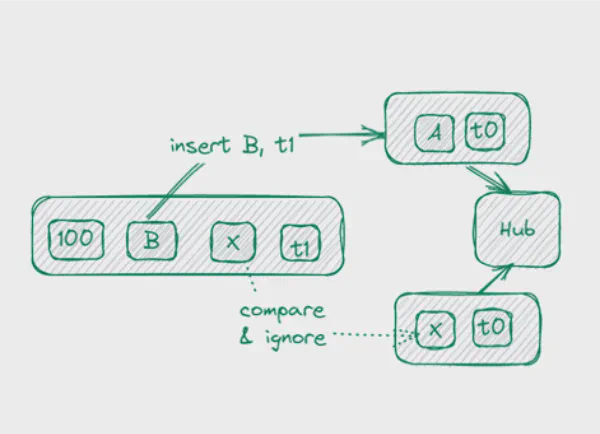
Správný přístup je použít multi-active satellite rozšířením klíče v satelitu o hash-key (HK), load-time a inscription time.
Při načítání dat nyní porovnáváme HK a inscription time stagovaných dat oproti datům ve vaultu, a pokud jsou atributy jiné nebo záznam chybí, jednoduše ho vložíme s aktuálním časovým razítkem jako load time.
Výhoda: stále můžeme použít pattern insert-only pro načítání satelitu.
Nevýhoda: nyní v něm máme bi-temporální historii. Pokud něco přijde mimo pořadí, je to v pořádku. Aktuální znalost o historii složíme až v době čtení.
To je ale problém při dotazování těchto dat. To lze vyřešit pomocí analytických funkcí pro particionování buď podle „hash & inscription time", nebo pouze podle „hash".
Nevýhodou je, že výkon může klesnout, pokud spojujete různé dotazy, z nichž každý používá analytickou funkci. Ale jak říká Markus Winand: „Use the index Luke!". To je to, co dělá PIT tabulka.
Naštěstí Patrick Cuba napsal zajímavý článek o použití sekvencí pro vytváření kompaktnějších PIT tabulek.
Zapadá řešení do DV2.0 frameworku? Tvrdil bych: ano. Bi-temporální satelit je speciální forma multi-active satelitu.
Komprese
Mohli byste předpokládat, že CDC stream vám dodává pouze relevantní změny. V realitě to vždy neplatí. Ale i když ano: jakmile začnete data dělit do různých satelitů, budou tam CDC řádky, které v daném satelitu nezpůsobí změnu. Takže musíme aplikovat kompresi.
Příchod mimo pořadí v kombinaci s kompresí
Ale jakmile dostanete znovu doručená data pro starší inscription time, může to způsobit vážné problémy, pokud ignorujete řádky pro určité satelity, protože neobsahovaly žádné nové informace. Pokud později přijde informace pro starší inscription time, mohlo by to způsobit chybná data. Proto musíme udržovat přehled o všech informacích, které jsme zkomprimovali, v tracking satelitu.
Zde příklad, kdy v t0, t1 a t2 byla doručena a zkomprimována hodnota „a". Nyní v pozdějším load time pro inscription time t1 je doručena hodnota „c". Tato hodnota bude vložena v inscription t1 do satelitu A TAKÉ v inscription time t2 hodnota „a", která byla dříve zkomprimována, musí být nyní vložena, protože se liší od hodnoty „c" v t1.
Pro naše německé čtenáře máme k dispozici video:
A co teď? Musím se starat o inscription time?
Ale Petře, vždy jsi kázal ignorovat inscription times; proč teď píšeš o tom, jak je ukládat a vyhodnocovat?
Zaprvé: vždy jsem upřesňoval, za jakých podmínek lze inscription time ignorovat.
Zadruhé: většina z vás by stále měla ve většině případů inscription time ignorovat.
Zatřetí: kariéru jsem začal v bankovnictví, takže chápu nutnost takových patternů.
Ale nyní, s rostoucí zákaznickou základnou pro náš software Datavault Builder, jsme dostali stále více požadavků na obecné řešení a po dlouhých návrhových a prototypových sezeních v posledních měsících jsme dospěli k závěru, že problém správně řeší pouze bi-temporální satelit, a to jsme udělali a vydali ve verzi 6.3 Datavault Builderu.
Poděkování patří Patricku Cubovi (Snowpit) a Thomasu Herzogovi (obecná myšlenka bi-temporálních satelitů jako speciálního typu multi-active satelitů) a Dirku Lernerovi (všechny jeho dokumenty o Multi-Temporalitě).
Vyzkoušejte Datavault Builder v akci
Živé demo. Upřímné odpovědi, zda je to pro váš tým.
Rezervovat bezplatné demo