Data Vault et stack Medallion de Databricks
Data Vault et Lakehouse sont souvent perçus comme des approches contradictoires. Ce webinaire montre que c'est l'inverse.

Pendant des années, une objection courante a empêché les équipes de combiner Data Vault et plateformes Lakehouse : trop de tables, trop de jointures, trop de complexité pour le big data. Dans ce webinaire, Simon Dudanski et Thomas Voigt de b.telligent ainsi que Petr Beles de Datavault Builder abordent cette idée reçue de front — et montrent pourquoi la combinaison de Data Vault 2.0 et de l’architecture Medallion de Databricks n’est pas un conflit, mais une combinaison de forces.
L’architecture Medallion en trois couches
Databricks organise les flux de données en trois responsabilités claires :
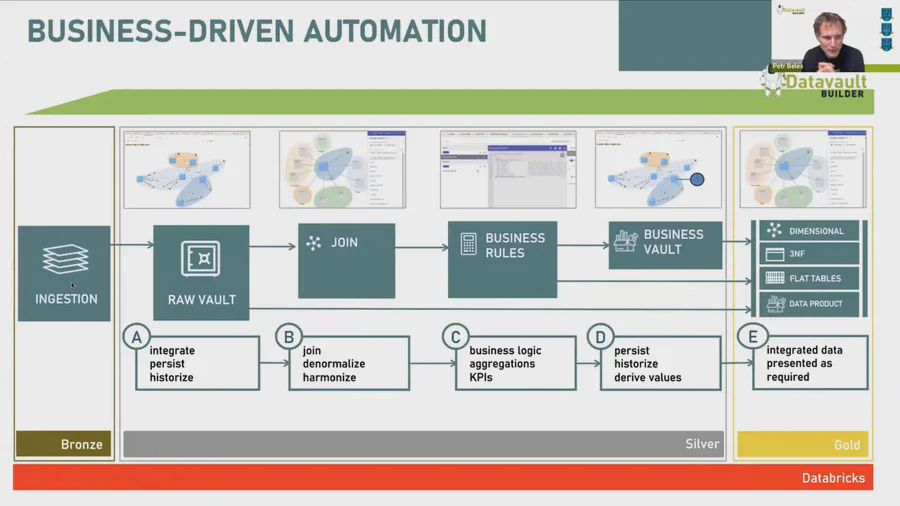
- Bronze — Données brutes, inchangées, historisées des systèmes sources. La zone d’atterrissage. Ingestion rapide, auditabilité totale.
- Silver — Données nettoyées, validées et intégrées. Le modèle métier central. Stable face aux changements de systèmes sources. Historique complet maintenu.
- Gold — Prêt pour la consommation, optimisé pour BI, IA/ML et data products. Les utilisateurs métier travaillent ici.
L’enseignement clé du webinaire : Silver est l’habitat naturel de Data Vault. Le Raw Vault correspond directement à la couche Silver. Le Business Vault se trouve juste au-dessus. Et la couche Gold — modèles dimensionnels, schémas en étoile, tables plates — peut être auto-générée par Datavault Builder à partir du même modèle sous-jacent.
Pourquoi Data Vault a sa place dans le stack Medallion
Trois piliers font de Data Vault la bonne approche de modélisation pour un Lakehouse moderne :
1. Compréhension uniforme des données Data Vault place le modèle métier au cœur de la plateforme — pas comme un artefact ponctuel, mais comme une structure vivante. Chaque hub, link et satellite est documenté automatiquement, et le data lineage va de la table source à la colonne du rapport sans effort manuel.
2. Règles métier modulaires Les besoins métier changent. Data Vault est conçu pour cela. Chaque règle métier vit isolément — vous pouvez ajouter, modifier ou retirer des règles sans casser le reste du modèle. Les tables plates et les modèles 3NF cassent face au changement. Data Vault, non.
3. Scalabilité entre modes de chargement Databricks apporte des outils puissants pour le batch et le streaming (Autoloader, Spark Streaming, Delta Live Tables). Les patterns bi-temporels de Data Vault — qui suivent à la fois quand les données sont arrivées et quand elles étaient vraies dans la source — gèrent les deux modes de chargement dans le même modèle. Les Hubs et Satellites accommodent naturellement la livraison hors ordre du streaming et la déduplication.
Parité fonctionnelle complète sur Databricks
Datavault Builder sur Databricks offre désormais la même couverture fonctionnelle que sur Snowflake, BigQuery, SQL Server et toutes les autres plateformes supportées. La démo en direct du webinaire parcourt l’intégralité du workflow :
- Modélisation conceptuelle — définissez visuellement les entités métier ; les tables Databricks sont créées en temps réel
- Staging / ingestion — connectez n’importe quelle source ; le code ETL/ELT est généré et exécuté automatiquement
- Chargement Raw Vault — Hubs, Links, Satellites chargés avec historisation complète et gestion des deltas
- Livraison de sortie — modèles dimensionnels et tables plates générés à partir du même modèle pour les outils BI (Power BI, Tableau, Qlik)
- Lineage et déploiement — documentation automatique, versioning Git, scripts de déploiement et de rollback ; API REST pour pipelines CI/CD
Un projet d’entreprise typique utilise 7 à 9 outils séparés pour couvrir ce processus. Avec Databricks et Datavault Builder, ce sont deux.
Le test de réalité pratique
Le webinaire conclut par une évaluation honnête de là où cette combinaison fonctionne le mieux :
- Projets batch-first ou streaming-first : les deux patterns fonctionnent. Pour 99 % des cas d’usage, le micro-batch à intervalles d'1 minute suffit — pas besoin de traitement temps réel pur.
- Environnements Databricks existants : Datavault Builder se connecte directement aux bases Unity Catalog existantes. Pas de migration nécessaire.
- Pipelines IA et ML : les data products de la couche Gold sont déjà structurés pour les feature stores et les modèles ML. La même fondation sert aux charges BI et IA.
Le message de Simon Dudanski, qui a passé une décennie à déconseiller la construction de Data Vault sur des plateformes big data, est désormais sans ambiguïté : « Mon univers est complet. J’ai tout ce dont j’ai besoin. »
Vous voulez voir comment Datavault Builder s’intègre à votre environnement Databricks ? Réservez une démo gratuite — nous parcourrons votre cas d’usage spécifique.
Voir Datavault Builder en action
Démo de 20 minutes. Réponses honnêtes sur l'adéquation avec votre équipe.
Réserver une démo gratuite