Data Vault y el stack Medallion de Databricks
Data Vault y Lakehouse suelen verse como enfoques contradictorios. Este webinar muestra que es justo lo contrario.

Durante años, una objeción común ha frenado a los equipos a la hora de combinar Data Vault con plataformas Lakehouse: demasiadas tablas, demasiados joins, demasiada complejidad para big data. En este webinar, Simon Dudanski y Thomas Voigt de b.telligent y Petr Beles de Datavault Builder abordan ese error de frente — y muestran por qué la combinación de Data Vault 2.0 y la arquitectura Medallion de Databricks no es un conflicto, sino una combinación de fortalezas.
La arquitectura Medallion en tres capas
Databricks organiza el flujo de datos en tres responsabilidades claras:
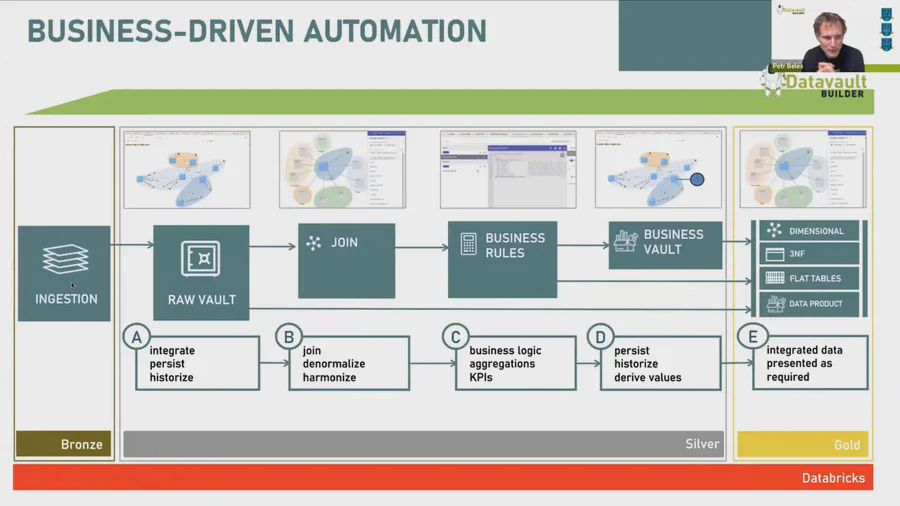
- Bronze — Datos en bruto, sin alterar, historiados desde los sistemas origen. La zona de aterrizaje. Ingesta rápida, plena auditabilidad.
- Silver — Datos limpios, validados e integrados. El modelo de negocio central. Estable frente a cambios de los sistemas origen. Historia completa mantenida.
- Gold — Listo para consumo, optimizado para BI, IA/ML y data products. Aquí trabajan los usuarios de negocio.
La idea clave del webinar: Silver es el hogar natural de Data Vault. El Raw Vault se mapea directamente a la capa Silver. El Business Vault se sitúa justo encima. Y la capa Gold — modelos dimensionales, esquemas en estrella, tablas planas — puede ser auto-generada por Datavault Builder a partir del mismo modelo subyacente.
Por qué Data Vault encaja en el stack Medallion
Tres pilares hacen de Data Vault el enfoque de modelado adecuado para un Lakehouse moderno:
1. Comprensión uniforme de los datos Data Vault sitúa el modelo de negocio en el corazón de la plataforma — no como un artefacto puntual, sino como una estructura viva. Cada hub, link y satélite se documenta automáticamente, y el linaje de datos va desde la tabla origen hasta la columna del informe sin esfuerzo manual.
2. Reglas de negocio modulares Los requisitos de negocio cambian. Data Vault está diseñado para ello. Cada regla de negocio vive aislada — puede añadir, cambiar o retirar reglas sin romper el resto del modelo. Las tablas planas y los modelos 3NF se rompen ante el cambio. Data Vault no.
3. Escalabilidad entre modos de carga Databricks aporta herramientas potentes tanto para ingesta batch como streaming (Autoloader, Spark Streaming, Delta Live Tables). Los patrones bi-temporales de Data Vault — que rastrean tanto cuándo llegaron los datos como cuándo eran ciertos en el origen — manejan ambos modos de carga en el mismo modelo. Los Hubs y Satellites acomodan de forma natural la entrega fuera de orden del streaming y la deduplicación.
Plena paridad funcional sobre Databricks
Datavault Builder sobre Databricks ofrece ahora la misma cobertura funcional que sobre Snowflake, BigQuery, SQL Server y todas las demás plataformas soportadas. La demo en vivo del webinar recorre el flujo completo:
- Modelado conceptual — defina entidades de negocio visualmente; las tablas Databricks se crean en tiempo real
- Staging / ingesta — conéctese a cualquier origen; el código ETL/ELT se genera y ejecuta automáticamente
- Carga del Raw Vault — Hubs, Links, Satellites cargados con historización completa y gestión de deltas
- Entrega de salida — modelos dimensionales y tablas planas generadas desde el mismo modelo para herramientas BI (Power BI, Tableau, Qlik)
- Linaje y despliegue — documentación automática, versionado Git, scripts de despliegue y rollback; API REST para pipelines CI/CD
Un proyecto enterprise típico usa entre 7 y 9 herramientas separadas para cubrir este proceso. Con Databricks y Datavault Builder, son dos.
La prueba práctica de realidad
El webinar cierra con una valoración honesta de dónde funciona mejor esta combinación:
- Proyectos batch-first o streaming-first: ambos patrones funcionan. Para el 99% de los casos, el micro-batch con intervalos de 1 minuto es suficiente — sin necesidad de procesamiento puramente real-time.
- Entornos Databricks existentes: Datavault Builder se conecta directamente a bases Unity Catalog existentes. No se requiere migración.
- Pipelines IA y ML: los data products de la capa Gold ya están estructurados para feature stores y modelos ML. La misma base sirve para cargas BI e IA.
El mensaje de Simon Dudanski, que pasó una década desaconsejando construir Data Vault sobre plataformas big data, es ahora inequívoco: «Mi mundo está completo. Tengo todo lo que necesito.»
¿Quiere ver cómo Datavault Builder encaja en su entorno Databricks? Reserve una demo gratuita — recorreremos su caso de uso concreto.
Vea Datavault Builder en acción
Demo en vivo. Respuestas honestas sobre si encaja con su equipo.
Reservar una Demo Gratuita